序言
在笔者的开发经历中,字符编码总是一个头疼的问题。而我们常见的编码格式有utf-8,gbk,ascii,unicode等,但是他们有什么区别呢,今儿抽了点时间仔细玩了玩。
常用的编码
- ASCII(American Standard Code for Information Interchange):美国信息交换标准代码,主要用于显示现代英语及其他西欧语言,是现今最通用的单字节编码系统。ASCII由美国国家标准学会制定,也就是大名鼎鼎的ANSI。其中0-31、127共33个为控制字符或通信专用字符,其余均为可显示字符 。其中ASCII又分为标准码和扩展码,标准码最高为即第八位为奇偶校验位,而扩展码 允许将第八位使用,用于附加的128个特殊的字符、外来字母以及图形。
- Unicode(统一码、万国码、单一 码):是计算机科学领域的一项业界标准,为每种语言中的每个字符设定了统一并且唯一的二进制编码,满足跨语言跨平台对文本进行转化。Unicode通常用两个字节表示一个字符,这使得原来英文编码(ASCII)从单字节变成了双字节,在变化过程中,只要把高字节全部填为0即可。总而言之,Unicode的诞生源于 多国语言 的编码统一需要,使得世界语言统一于一种编码体系下
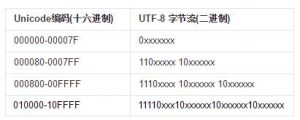
- UTF-8(Unicode Transformation Format-8):翻译过来就是Unicode字符集转换格式,简而言之,UTF-8是Unicode下的一个儿子。UTF-8以字节为单位对Unicode进行编码。UTF-8的最大特点是,对不同范围的字符使用不同长度的编码,对于0x00-0x7F之间的字符,UTF-8与ASCII编码完全相同,通过对高位的特定组合以及实现不同范围不同长度,但要注意的是UTF-8最长的长度是四个字节。从下表也可以得出结论,110开头作为一个字符的开始,10开头为其尾随的扩展。通过解析字节中110开头的数量,可对字节流进行分割。
编码与解码
工欲善其事,必先利其器。在这一节中,有了编码,自然就有了解码。
编码:字符串编程字节数组 String–>byte数组,str.getBytes();
解码:字节数组编程字符串 byte–>String
解码的过程应当根据编码的特点,进行适当的选择,如果选择不当极易出现乱码的情况
例如截取某一字符串字符串数组的前三个字节11100100 10111000 10001010,这几个字节在GBK下(2字节)对应涓(11100100 10111000),在UTF-8下对应上(11100100 10111000 10001010)在下一节中,我们将通过程序进行验证。
实验理解
- 理解编码
为了方便我们对编码的理解,我们先将字符串转换为相应的字节数组,进而得到各自的编码,在这儿我们以Java语言String的getBytes()方法进行解析,将字符串进行转换。【注:getBytes(“gbk”)表示以gbk解码,若不填参数默认utf-8】
通过编程,最终输出
[上海]的UTF8二进制编码如下:
11100100
10111000
10001010
11100110
10110101
10110111
共9个字节,即在utf-8下,三个字节对应于一个字符。
即11100100 10111000 10001010在UTF-8下对应[上]
- UTF-8与GBK
在上一小节中,我们输入的字符以默认UTF-8的形式存在,但是我们平常经常会引起乱码,比如以上海为例,会乱码显示为[涓婃捣],面对这个问题,我们首先要注意到,原来的[上海]两个字的字符串在UTF-8下共有6个字节数组,而[涓婃捣]有三个字符,恰好每个字符对应两个字节数组,这让我门可以想到,会不会是误用了GBK的解码方式对UTF-8字节数组进行了解码【笔者注,[上海好]三个字符在UTF-8下对应9个字节数组,这个时候用GBK去解析,末尾会出现一个问号,即4个乱码字符+问号的形式出现】
下面我们以gbk的方式对[上海]进行解码【getBytes(“gbk”),用这个方法可能会抛出异常,我们必须在用到这个方法的函数申明中加上throws Exception】,得到如下结果
[上海]的GBK二进制编码如下:
11001001
11001111
10111010
10100011
上面是用GBK对[上海]进行解码的效果,GBK让一个字符对应于两个字节数组
我们既然怀疑是用GBK的方式解码了UTF-8编码的字符,我们再来看一下[涓婃捣]他的GBK编码。
[涓婃捣]的GBK二进制编码如下:
11100100
10111000
10001010
11100110
10110101
10110111
[上海]的UTF8二进制编码如下:
11100100
10111000
10001010
11100110
10110101
10110111
将这两个对比发现一模一样,我们的假设得到了验证。
总结
因此,当我们什么时候遇到乱码的时候,不要慌张,可以先分析乱码显示的字符数和预期显示的字符数之间的关系,通过这个关系可以推断出在解码过程中哪儿出现了问题,并及时改正,在网络编程中,如PHP开发中,我们经常在开始加上header(“Content-type:text/html;charset=utf-8”)定义整个文件的编码格式,在与之对应的HTML中,我们常加上<meta http-equiv=’Content-Type’ content=’text/html; charset=utf-8′ />来定义页面的编码为UTF8。而在一些网络通信编程中,我们要时刻注意我们接收到的数据帧的编码格式为何种,并选择正确的解码标准对其解码。
